 Hilfe
Hilfe

 Neues Thema
Neues Thema
Ich bin da ganz bei Dir, Innovation ist gut und richtig und das aktuelle "Win10 kann doch schon..." geht mir gehörig auf den Zeiger.
Ich sag auch nicht, daß O&O was falsch macht. Sie schwimmen aber erstmal gegen den Strom, und während das in sich eine gute Sache ist, so heißt es halt auch, daß sie damit automatisch in Frage gestellt werden.
Qui bono? O&O.
Win10 Shutup? O&O.
Ausrichtung auf HDD-spezifische Produkte? O&O.
Demgegenüber dann die bewußte Erklärung, daß die aktuell vorherrschende Meinung, SSDs nicht weiter optimieren zu müssen (wohlgemerkt mit Konnotation "soll man machen" und nicht "kann man machen, wenn man möchte") einerseits und gleichzeitiges Schuldigbleiben einer Erklärung andererseits, sodaß am Ende eine kritische Frage unbeantwortet bleibt: wie soll das gehen, was die da behaupten, wenn exakt das technisch eigentlich ausgeschlossen sein sollte?
Schaun wir uns doch nur hier im Forum um, oder in anderen IT-orientierten Foren. Der informierte Leser sieht recht schnell, daß Fehlinformationen, Halb- und Garkeinwissen vorherrschend sind und wird irgendwann (wenn nicht schon geschehen) feststellen, daß (a) die IT-Industrie exakt davon profitiert und/oder (b) dabei noch gehörig nachhilft. Schließlich bringt Support Geld und mit dem Nichtwissen Anderer läßt sich eine dicke Stange Geld verdienen.
"Ich hab noch nie AV-Software benutzt und hatte noch nie einen Virus" ist nur eines von ganz vielen Beispielen. Offensichtlich reicht die graue Materie nicht weit genug um zu kapieren, daß man ohne die AV-Software den potentiellen Virus natürlich nicht sehen wird, besonders dann nicht, wenn dieser nicht gesehen werden *will*. Macht aber nichts, weil exakt solchen Kollegen kann man effektiv alles unterschieben und sich an ihnen bereichern, egal ob "legitim" (per Supportleistung) oder nicht (per Phishing, Ransomware oder einfach nur irgendwelchen abgesammelten Daten von irgendwo).
Daran muß sich O&O an der Stelle messen. Es ist schön, daß sie jetzt Waschbretter aus Bambus verkaufen, da das besser für die Klamotten ist... nur dumm, daß die breite Masse Waschmaschinen verwendet.
SSD defragmentieren
#76
 RalphS
RalphS 
- Gruppe: VIP Mitglieder
- Beiträge: 8.902
- Beigetreten: 20. Juli 07
- Reputation: 1.126
- Geschlecht:Männlich
- Wohnort:Zuhause
- Interessen:Ja
geschrieben 05. September 2019 - 22:24
"If you give a man a fish he is hungry again in an hour. If you teach him to catch a fish you do him a good turn."-- Anne Isabella Thackeray Ritchie


#77
thielemann03

- Gruppe: aktive Mitglieder
- Beiträge: 1.704
- Beigetreten: 28. Januar 19
- Reputation: 205
- Geschlecht:Männlich
- Wohnort:Marksuhl
- Interessen:Garten, Simson Vogelserie, CAD, Kaninchenzucht(rheinische Schecken)
geschrieben 05. September 2019 - 23:01
Im Moment glaube ich auch nicht so recht daran, aber vielleicht kommen ja bald Erfahrungsberichte. Ich werde es nicht schlecht reden, oder loben, weil ich es nicht kenne. Dass ich ich es brauchen würde, sehe ich auch nicht und die Zeiten, in denen ich mir mein System kaputtoptimierte, sind vorbei.
Sollte es an dieser Front Gutes zu berichten geben, nehme ich das gerne auf, aber vorerst lasse ich es beim Status Quo.
Sollte es an dieser Front Gutes zu berichten geben, nehme ich das gerne auf, aber vorerst lasse ich es beim Status Quo.
Dieser Beitrag wurde von thielemann03 bearbeitet: 06. September 2019 - 15:54
Niemand ist so gut, wie ich sein könnte.
#78 _Tumultus_
geschrieben 06. September 2019 - 14:18
"Was ist mit SSDs - profitieren sie von einer Defragmentierung? Die einfache Antwort lautet nein. Die gesamte Grundlage fragmentierter Daten beruht auf der Tatsache, dass Ihr Speichergerät bewegliche Teile verwendet, um auf Daten zuzugreifen. Da SSDs keine beweglichen Teile haben, also Solid State, gibt es keine Suchzeit oder Rotationslatenz."
Source (Englisch): https://www.pcgamer....-defrag-my-ssd/
Source (Englisch): https://www.pcgamer....-defrag-my-ssd/
#79
Doodle

- Gruppe: aktive Mitglieder
- Beiträge: 4.785
- Beigetreten: 09. Februar 12
- Reputation: 870
- Geschlecht:Männlich
geschrieben 06. September 2019 - 19:44
 Zitat (Tumultus: 06. September 2019 - 14:18)
Zitat (Tumultus: 06. September 2019 - 14:18)
"Was ist mit SSDs - profitieren sie von einer Defragmentierung? Die einfache Antwort lautet nein. Die gesamte Grundlage fragmentierter Daten beruht auf der Tatsache, dass Ihr Speichergerät bewegliche Teile verwendet, um auf Daten zuzugreifen. Da SSDs keine beweglichen Teile haben, also „Solid State“, gibt es keine Suchzeit oder Rotationslatenz."
Ja, ja ... was der Großvater noch wusste ... und die SPD ist eine Volkspartei ... lustich, nich?
Das hat doch mit dem normalen Defragmentieren gar nichts mehr zu, um was es hier geht.
Dieser Beitrag wurde von Doodle bearbeitet: 06. September 2019 - 20:18
#80
RalphS
- Gruppe: VIP Mitglieder
- Beiträge: 8.902
- Beigetreten: 20. Juli 07
- Reputation: 1.126
- Geschlecht:Männlich
- Wohnort:Zuhause
- Interessen:Ja
geschrieben 06. September 2019 - 20:53
Die zitierte Erklärung ist halt leider auch Käse, auf Otto Normalo getrimmt. Schade -- heutuztage ist es wichtiger, mit RGB Augenwischerei zu betreiben, für das, was man da hat, interessiert sich keiner.
SSD sind funktional SRAM. Einige von uns werden sich vielleicht noch an statischen RAM erinnern, der mal Allheilmittel für alles sein sollte, und ein paar mehr erinnern sich vielleicht auch an die verzweifelten Versuche, PROM ausreichend schnell zu kriegen -- es ist gar nicht soo lange her, daß PROM weit hinter Festplatten zurückblieb und der Anspruch nur war, "bewegungsfreie Festplatten" zumindest in etwa so schnell wie "richtige" Festplatten zu bekommen. Von "signifikant schneller" war damals noch nicht mal im Ansatzh die Rede.
Die Grundlage fragmentierter Daten leitet sich vom Paging her. RAM und Dateidaten wurden mal ganz zu Anfang als Einheit geschrieben. Speicherseiten oder Cluster gab es nicht. Das führte dazu, daß große Bereiche im Speicher - fest oder dynamisch -- unbenutzbar blieben. 100MB Platz und das Datenobjekt war 100-plus-ein-halbes-Kilobyte? Paßt nicht: "Nicht genügend Speicher".
Paging (im RAM) und Clustering (im Dateisystem) half dagegen. Daten wurden nun seitenweise geschrieben. Wie ein Buch wurde das Datum in fest definierte Einheiten (Pages) segmentiert. Das überzählige halbe KB honnte einfach woanders gespeichert werden. Problem gelöst.
Auf dem Datenträger passierte dasselbe. Es gab "Seiten" (an dieser Stelle Cluster genannt) mit einer fest definierten Größe als Einzelteile jedes Datums. Seit LBA werden die einfach der Reihe nach gespeichert. Cluster 1, Cluster 2, Cluster 3 und so weiter bis der Datenträger vollständig adressiert ist. Cluster 1 hat ein Stück autoexec.bat. Cluster 2 hat ein Stück config.sys. Cluster 3 hat ein weiteres Stück der config.sys. Cluster 4 und 5 haben jeweils ein Stück msdos.sys. Und so weiter. Jeder Cluster hat exakt einen Teil eines Datums. Kein Cluster beinhaltet mehrere Dateifragmente, aber jeder Cluster hat eine Endekennung, die entweder auf den nächstfolgenden Cluster verweist oder das Datum terminiert (cf end-of-file marker).
Daten werden gelesen. Dabei verändert sich am Zustand des Datums und seiner Cluster nichts. Sie werden aber auch geschrieben, gelöscht(freigegeben) und verändert. Vormals belegte Cluster werden freigegeben und freie Cluster nun dem geänderten Datum zugeordnet. Cluster 1, 2 und 3 haben jetzt einen anderen Inhalt oder gar keinen (definierten) mehr. Das ist umgezogen in Cluster 4234.
Und irgendwann hab ich eine Datei, die 10 Megabytes belegt. Diese belegt zur Veranschauung 2560 Cluster. Wo diese Cluster liegen... weiß kein Mensch.
-A- können sie alle hintereinander angeordnet sein (physikalisch auf dem Datenträger). Es gibt ein Fragment, die Datei ist "defragmentiert".
-B- können alle zugehörigen 2560 Cluster irgendwo willkürlich auf dem Datenträger verteilt sein. Es gibt 2560 Fragmente. Die Datei ist "fragmentiert".
-C- Alles dazwischen. Ein paar Cluster hängen zusammen. Andere nicht.
An der Stelle sei angemerkt, daß die Reihenfolge der belegten Cluster *nicht das Geringste* mit dem Dateiinhalt oder irgendwas zu tun hat. Der erste Cluster der Datei kann hinter alle anderen liegen und der letzte davor. Im allgemeinen sind Clusterketten zusammenhängend (aufeinanderfolgende Cluster sind physisch und logisch sortiert). Aber auch das muß nicht der Fall sein, Cluster 1 kann den Anfang der Datei haben und Cluster 2 das Ende und alle Cluster dazwischen befinden sich sonstwo.
Wenn wir jetzt die Datei aus (-A-) hernehmen und lesen, müssen wir den ersten Cluster der Datei suchen. Das dauert eine gewisse Suchzeit S. Der nächste Cluster befindet sich dahinter => keine Suchzeit. Der nächste wieder da dahinter - wieder keine Suchzeit. Und so weiter bis wir alle haben. Effektiv mußten wir nur den ersten Cluster suchen. Der Rest kann einfach seriell gelesen werden.
Die Lesedauer für diesen Fall ist damit ausschließlich abhängig von der Dateilänge. Ich hab 2560 Cluster, die muß ich alle lesen; die eine Suchzeit am Anfang fällt nicht ins Gewicht. Nehmen wir eine Suchzeit von 10ms an und eine Lesezeit von 1ms, dann haben wir 10ms Suchen plus 2560ms Lesen gleich nicht-ganz-drei-Sekunden, bis die Datei vollständig vom Datenträger gelesen ist.
Fall (-B-) als zweites Extremum sieht anders aus. Zuerst suche ich den ersten Cluster der Datei. Dort steht drin, daß der zweite Cluster woanders ist. Also muß ich den wieder suchen. Dann suche ich den dritten, vierten usw. bis zum 2560. Cluster.
Die Lesedauer für diesen Fall ist abhängig von der Anzahl der Fragmente, effektiv ist das jedes Mal die initiale Suchzeit nach dem ersten Cluster. Die Länge der Datei ist nicht mehr relevant. Dieselbe Datei wird für einen Lesevorgang signifikant länger brauchen als im Fall (-A-), abgeschätzt durch den Faktor Fragmentzahl mal Random Seek Times. Wenn wir für Seek wieder 10ms veranschlagen und fürs Lesen 1ms, benötigt das Lesen der Datei 25600ms Suchen plus 2560ms Lesen, das ist eine knappe halbe Minute.
Bei SSDs ist die Situation ein wenig anders gelagert. Es gibt keine Suchzeiten, aber es gibt Unterschiede in den Zugriffszeiten nach belegter Zelle. Multi-level cells als alles-was-nicht-single-level ist kann nun verschiedene Dateifragmente halten. Bei SLC geht das nicht, da ist exakt ein Dateifragment drin oder gar nichts.
Wenn ich jetzt meine 10MB-Datei hernehme, dann kann es mir bei MLC passieren, daß sie "optimal verteilt" ist (Fall "X"). Optimal heißt hier: Alle meine MLC-Zellen, die ich lese, beinhalten Teile meiner Datei und nur Teile meiner Datei, aber keine anderen.
Es kann aber auch sein (Fall "Y") daß dem exakt nicht so ist. Schlimmstenfalls hält jede MLC-Zelle nur exakt ein Fragment meiner Datei.
Ich kann aber Zellen nicht anteilig lesen. Ich muß die ganze Zelle lesen, und ich muß sie sogar noch zurückschreiben, damit der Inhalt nicht verlorengeht. Je mehr Platz meine multi-level Zelle mir bietet, je mehr ich da reinstopfen kann, desto größer ist das Risiko, daß ich "Verschnitt" lese: daß ich also statt der benötigten 10MB Lesevolumen stattdessen 50MB oder 100MB oder sonstwieviel lesen muß. Dieser Verschnitt nützt mir nichts, ich muß ihn hinterher verwerfen, aber ich kann ihn auch nicht ignorieren.
Exakt HIER kann man mit Optimierungsarbeit ansetzen, beispielsweise mit SOLID in Zusammenarbeit mit dem SSD-Controller. Unter der Annahme, daß SSD-Controller und Software gut genug zusammenarbeiten, kann ggfs. die 10MB-Datei in so wenig Zellen wie möglich gesteckt werden, damit jener Verschnitt eben NICHT mehr mitgelesen werden muß.
Die Frage ist aber natürlich, ob und wie sich das auf die Performance auswirkt. Es darf davon ausgegangen werden, daß etwaige Performancegewinne nur bei ausreichend großem Lesevolumen auch nur potentiell relevant werden: wenn wir eine Lesegeschwindigkeit von 500MB/s annehmen und wir "optimalerweise" exakt 1000MB lesen, dann dauert das zwei Sekunden, bis die Datei vollständig gelesen ist; unterstellen wir Platz für vier Dateifragmente pro Zelle, von denen nur eines benötigt wird, lesen wir schlimmstenfalls 4000 MB und brauchen nun die vierfache Menge der Zeit (8 Sekunden) was netto etwa 125MB/s entspricht (worst case).
Performanceverluste sind an dieser Stelle insbesondere von der Speichertiefe der Zellen abhängig.
Ergo, nein, Fragmentierung hat mit Rotation überhaupt nichts zu tun (allerdings wirkt sich zunehmende Fragmentierung auf Suchzeiten aus und die gibt's insbesondere bei rotierenden Datenträgern).
Und ebenso nein, "funktioniert schon so alles bei SSD" gilt definitiv auch nicht. Optimierungsansätze sind sinnvoll. Die Frage ist nur, ob sie sich lohnen. Für SSDs im Datenzentrum gilt das sehr wahrscheinlich - hier zählt jedes einzelne Bit. Aber zuhause sieht das ganz anders aus.
SSD sind funktional SRAM. Einige von uns werden sich vielleicht noch an statischen RAM erinnern, der mal Allheilmittel für alles sein sollte, und ein paar mehr erinnern sich vielleicht auch an die verzweifelten Versuche, PROM ausreichend schnell zu kriegen -- es ist gar nicht soo lange her, daß PROM weit hinter Festplatten zurückblieb und der Anspruch nur war, "bewegungsfreie Festplatten" zumindest in etwa so schnell wie "richtige" Festplatten zu bekommen. Von "signifikant schneller" war damals noch nicht mal im Ansatzh die Rede.
Die Grundlage fragmentierter Daten leitet sich vom Paging her. RAM und Dateidaten wurden mal ganz zu Anfang als Einheit geschrieben. Speicherseiten oder Cluster gab es nicht. Das führte dazu, daß große Bereiche im Speicher - fest oder dynamisch -- unbenutzbar blieben. 100MB Platz und das Datenobjekt war 100-plus-ein-halbes-Kilobyte? Paßt nicht: "Nicht genügend Speicher".
Paging (im RAM) und Clustering (im Dateisystem) half dagegen. Daten wurden nun seitenweise geschrieben. Wie ein Buch wurde das Datum in fest definierte Einheiten (Pages) segmentiert. Das überzählige halbe KB honnte einfach woanders gespeichert werden. Problem gelöst.
Auf dem Datenträger passierte dasselbe. Es gab "Seiten" (an dieser Stelle Cluster genannt) mit einer fest definierten Größe als Einzelteile jedes Datums. Seit LBA werden die einfach der Reihe nach gespeichert. Cluster 1, Cluster 2, Cluster 3 und so weiter bis der Datenträger vollständig adressiert ist. Cluster 1 hat ein Stück autoexec.bat. Cluster 2 hat ein Stück config.sys. Cluster 3 hat ein weiteres Stück der config.sys. Cluster 4 und 5 haben jeweils ein Stück msdos.sys. Und so weiter. Jeder Cluster hat exakt einen Teil eines Datums. Kein Cluster beinhaltet mehrere Dateifragmente, aber jeder Cluster hat eine Endekennung, die entweder auf den nächstfolgenden Cluster verweist oder das Datum terminiert (cf end-of-file marker).
Daten werden gelesen. Dabei verändert sich am Zustand des Datums und seiner Cluster nichts. Sie werden aber auch geschrieben, gelöscht(freigegeben) und verändert. Vormals belegte Cluster werden freigegeben und freie Cluster nun dem geänderten Datum zugeordnet. Cluster 1, 2 und 3 haben jetzt einen anderen Inhalt oder gar keinen (definierten) mehr. Das ist umgezogen in Cluster 4234.
Und irgendwann hab ich eine Datei, die 10 Megabytes belegt. Diese belegt zur Veranschauung 2560 Cluster. Wo diese Cluster liegen... weiß kein Mensch.
-A- können sie alle hintereinander angeordnet sein (physikalisch auf dem Datenträger). Es gibt ein Fragment, die Datei ist "defragmentiert".
-B- können alle zugehörigen 2560 Cluster irgendwo willkürlich auf dem Datenträger verteilt sein. Es gibt 2560 Fragmente. Die Datei ist "fragmentiert".
-C- Alles dazwischen. Ein paar Cluster hängen zusammen. Andere nicht.
An der Stelle sei angemerkt, daß die Reihenfolge der belegten Cluster *nicht das Geringste* mit dem Dateiinhalt oder irgendwas zu tun hat. Der erste Cluster der Datei kann hinter alle anderen liegen und der letzte davor. Im allgemeinen sind Clusterketten zusammenhängend (aufeinanderfolgende Cluster sind physisch und logisch sortiert). Aber auch das muß nicht der Fall sein, Cluster 1 kann den Anfang der Datei haben und Cluster 2 das Ende und alle Cluster dazwischen befinden sich sonstwo.
Wenn wir jetzt die Datei aus (-A-) hernehmen und lesen, müssen wir den ersten Cluster der Datei suchen. Das dauert eine gewisse Suchzeit S. Der nächste Cluster befindet sich dahinter => keine Suchzeit. Der nächste wieder da dahinter - wieder keine Suchzeit. Und so weiter bis wir alle haben. Effektiv mußten wir nur den ersten Cluster suchen. Der Rest kann einfach seriell gelesen werden.
Die Lesedauer für diesen Fall ist damit ausschließlich abhängig von der Dateilänge. Ich hab 2560 Cluster, die muß ich alle lesen; die eine Suchzeit am Anfang fällt nicht ins Gewicht. Nehmen wir eine Suchzeit von 10ms an und eine Lesezeit von 1ms, dann haben wir 10ms Suchen plus 2560ms Lesen gleich nicht-ganz-drei-Sekunden, bis die Datei vollständig vom Datenträger gelesen ist.
Fall (-B-) als zweites Extremum sieht anders aus. Zuerst suche ich den ersten Cluster der Datei. Dort steht drin, daß der zweite Cluster woanders ist. Also muß ich den wieder suchen. Dann suche ich den dritten, vierten usw. bis zum 2560. Cluster.
Die Lesedauer für diesen Fall ist abhängig von der Anzahl der Fragmente, effektiv ist das jedes Mal die initiale Suchzeit nach dem ersten Cluster. Die Länge der Datei ist nicht mehr relevant. Dieselbe Datei wird für einen Lesevorgang signifikant länger brauchen als im Fall (-A-), abgeschätzt durch den Faktor Fragmentzahl mal Random Seek Times. Wenn wir für Seek wieder 10ms veranschlagen und fürs Lesen 1ms, benötigt das Lesen der Datei 25600ms Suchen plus 2560ms Lesen, das ist eine knappe halbe Minute.
Bei SSDs ist die Situation ein wenig anders gelagert. Es gibt keine Suchzeiten, aber es gibt Unterschiede in den Zugriffszeiten nach belegter Zelle. Multi-level cells als alles-was-nicht-single-level ist kann nun verschiedene Dateifragmente halten. Bei SLC geht das nicht, da ist exakt ein Dateifragment drin oder gar nichts.
Wenn ich jetzt meine 10MB-Datei hernehme, dann kann es mir bei MLC passieren, daß sie "optimal verteilt" ist (Fall "X"). Optimal heißt hier: Alle meine MLC-Zellen, die ich lese, beinhalten Teile meiner Datei und nur Teile meiner Datei, aber keine anderen.
Es kann aber auch sein (Fall "Y") daß dem exakt nicht so ist. Schlimmstenfalls hält jede MLC-Zelle nur exakt ein Fragment meiner Datei.
Ich kann aber Zellen nicht anteilig lesen. Ich muß die ganze Zelle lesen, und ich muß sie sogar noch zurückschreiben, damit der Inhalt nicht verlorengeht. Je mehr Platz meine multi-level Zelle mir bietet, je mehr ich da reinstopfen kann, desto größer ist das Risiko, daß ich "Verschnitt" lese: daß ich also statt der benötigten 10MB Lesevolumen stattdessen 50MB oder 100MB oder sonstwieviel lesen muß. Dieser Verschnitt nützt mir nichts, ich muß ihn hinterher verwerfen, aber ich kann ihn auch nicht ignorieren.
Exakt HIER kann man mit Optimierungsarbeit ansetzen, beispielsweise mit SOLID in Zusammenarbeit mit dem SSD-Controller. Unter der Annahme, daß SSD-Controller und Software gut genug zusammenarbeiten, kann ggfs. die 10MB-Datei in so wenig Zellen wie möglich gesteckt werden, damit jener Verschnitt eben NICHT mehr mitgelesen werden muß.
Die Frage ist aber natürlich, ob und wie sich das auf die Performance auswirkt. Es darf davon ausgegangen werden, daß etwaige Performancegewinne nur bei ausreichend großem Lesevolumen auch nur potentiell relevant werden: wenn wir eine Lesegeschwindigkeit von 500MB/s annehmen und wir "optimalerweise" exakt 1000MB lesen, dann dauert das zwei Sekunden, bis die Datei vollständig gelesen ist; unterstellen wir Platz für vier Dateifragmente pro Zelle, von denen nur eines benötigt wird, lesen wir schlimmstenfalls 4000 MB und brauchen nun die vierfache Menge der Zeit (8 Sekunden) was netto etwa 125MB/s entspricht (worst case).
Performanceverluste sind an dieser Stelle insbesondere von der Speichertiefe der Zellen abhängig.
Ergo, nein, Fragmentierung hat mit Rotation überhaupt nichts zu tun (allerdings wirkt sich zunehmende Fragmentierung auf Suchzeiten aus und die gibt's insbesondere bei rotierenden Datenträgern).
Und ebenso nein, "funktioniert schon so alles bei SSD" gilt definitiv auch nicht. Optimierungsansätze sind sinnvoll. Die Frage ist nur, ob sie sich lohnen. Für SSDs im Datenzentrum gilt das sehr wahrscheinlich - hier zählt jedes einzelne Bit. Aber zuhause sieht das ganz anders aus.
"If you give a man a fish he is hungry again in an hour. If you teach him to catch a fish you do him a good turn."-- Anne Isabella Thackeray Ritchie
#81
Gispelmob

geschrieben 07. September 2019 - 06:41
Hier greife ich mal dein "Die Frage ist nur, ob sie sich lohnen." auf.
SSDs sind von Haus aus bereits schnell, die PCIe Modelle sogar extrem schnell.
Was verspricht man sich also davon, wenn eine Software die SSD "optimiert" und diese dann vielleicht 1% schneller wird. Wenn die Schnittstelle von der SSD bereits auf maximaler Geschwindigkeit genutzt wird, dann wird eine solche Prozent absolut nichts bewirken, außer dass die Software dafür gesorgt hat, dass mehr Daten geschrieben wurden als eigentlich geschrieben werden mussten und somit die SSD schneller "altert" bzw schnneller an ihrem gerantiertem TBW Wert ist.
Für mich kommt eine Zusatzsoftware nicht in Frage. Der Nutzen ist für mich im Bereich von Rechenfehlern.
SSDs sind von Haus aus bereits schnell, die PCIe Modelle sogar extrem schnell.
Was verspricht man sich also davon, wenn eine Software die SSD "optimiert" und diese dann vielleicht 1% schneller wird. Wenn die Schnittstelle von der SSD bereits auf maximaler Geschwindigkeit genutzt wird, dann wird eine solche Prozent absolut nichts bewirken, außer dass die Software dafür gesorgt hat, dass mehr Daten geschrieben wurden als eigentlich geschrieben werden mussten und somit die SSD schneller "altert" bzw schnneller an ihrem gerantiertem TBW Wert ist.
Für mich kommt eine Zusatzsoftware nicht in Frage. Der Nutzen ist für mich im Bereich von Rechenfehlern.
AMD Ryzen 9 5950X, Asus ROG Strix X570-F Gaming, 32GB Corsair DDR4-3200, Asus Geforce GTX 3060 12GB, Creative Sound Blaster AE-7, 240GB SSD, 500GB SSD, 3x 1TB SSD, Win11 Home, 4x Acer G246HL Bbid, Logitech MX518 Gaming Mouse, Logitech G440 Mousepad, Logitech K120 Keyboard, Razer Tiamat 7.1 V2 Headset, Creative Inspire 5.1 5300 Soundsystem
#82
Sarek

- Gruppe: aktive Mitglieder
- Beiträge: 759
- Beigetreten: 16. April 18
- Reputation: 245
- Geschlecht:Männlich
geschrieben 07. September 2019 - 13:34
Zitat (Gispelmob: 07. September 2019 - 06:41)
Was verspricht man sich also davon, wenn eine Software die SSD "optimiert" und diese dann vielleicht 1% schneller wird.
Der "Ordnungswahn" / "Macht der Gewohnheit" gerade von älteren Nutzern!
Ich habe es bei meinem Vater gesehen, der zur guten alten Windows98-Zeit jeden (!) Freitag die Datenträgerdefragmentierung gestartet hat. Egal ob er die Woche überhaupt am PC war oder nicht.
Das hat er bis Win7 auch so durchgezogen.
Ich selbst habe maximal 2x im Jahr die HDD defragmentiert und ab Win2000 gar nicht mehr. Ab 2000 habe ich da schon den Mehrwert sprich Geschwindigkeitsschub nicht mehr gespürt. Unter 98-Me war die Defragmentierung in der Tat hilfreich. Gerade bei den Uraltplatten

Dieser Beitrag wurde von Sarek bearbeitet: 07. September 2019 - 17:14
_________________________
Arbeitstier 1: i5 9400f (6x2,9 GHz), 32 GB RAM, 512 GB SSD, 2 TB HDD, 1.44 MB FDD
Arbeitstier 2: Xeon E3 1230 V3 (4x3,0 GHz), 16 GB RAM, 512 GB SSD, 2 TB HDD
Arbeitstier 3: Intel Xeon E5450 (4x3 GHz), 16 GB DDR3, 120 GB SSD, 500 GB HDD
Arbeitstier 4: T61 mit T9500 (2x2,6 GHz), 8 GB RAM, 120 GB SSD
Alle mit Windows 10
Arbeitstier 1: i5 9400f (6x2,9 GHz), 32 GB RAM, 512 GB SSD, 2 TB HDD, 1.44 MB FDD
Arbeitstier 2: Xeon E3 1230 V3 (4x3,0 GHz), 16 GB RAM, 512 GB SSD, 2 TB HDD
Arbeitstier 3: Intel Xeon E5450 (4x3 GHz), 16 GB DDR3, 120 GB SSD, 500 GB HDD
Arbeitstier 4: T61 mit T9500 (2x2,6 GHz), 8 GB RAM, 120 GB SSD
Alle mit Windows 10
#83
Stefan_der_held


- Gruppe: Offizieller Support
- Beiträge: 14.344
- Beigetreten: 08. April 06
- Reputation: 888
- Geschlecht:Männlich
- Wohnort:Dortmund NRW
- Interessen:Alles wo irgendwie Strom durchfließt fasziniert mich einfach weswegen ich halt Elektroinstallateur geworden bin :)
geschrieben 07. September 2019 - 15:25
Zitat (Sarek: 07. September 2019 - 13:34)
Der "Ordnungswahn" gerade von älteren Nutzern!
Nennen wir es besser "Macht der Gewohnheit".
Ich kann es persönlich allerdings nicht gut-heißen wenn Hersteller meinen dort unsinnigen (wenn nicht sogar für die Hardware destruktiven) Profit raus zu schlagen...
#84
thielemann03
- Gruppe: aktive Mitglieder
- Beiträge: 1.704
- Beigetreten: 28. Januar 19
- Reputation: 205
- Geschlecht:Männlich
- Wohnort:Marksuhl
- Interessen:Garten, Simson Vogelserie, CAD, Kaninchenzucht(rheinische Schecken)
geschrieben 07. September 2019 - 16:03
M.E. geht es nicht so sehr um Hardware, eher um Blauäugikeit.
Niemand ist so gut, wie ich sein könnte.
#85
Doodle
- Gruppe: aktive Mitglieder
- Beiträge: 4.785
- Beigetreten: 09. Februar 12
- Reputation: 870
- Geschlecht:Männlich
geschrieben 07. September 2019 - 19:48
Zitat (Gispelmob: 07. September 2019 - 06:41)
... außer dass die Software dafür gesorgt hat, dass mehr Daten geschrieben wurden als eigentlich geschrieben werden mussten und somit die SSD schneller "altert" bzw schnneller an ihrem gerantiertem TBW Wert ist.
Wie kommst du da drauf? Kannst du deine Aussage belegen? Nach Angaben des Herstellers soll ja gerade so etwas vermieden werden.
Ich finde es wirklich etwas schwierig, wenn neue Entwicklungen von vornherein mit alten Weisheiten als Unsinn abgetan werden. Vielleicht ist die Software okay, vielleicht auch nicht.
Aber die Sprüche Schlangenöl etc. sind kein Argument, sondern nur das Runterbrabbeln von Stammtischsprüchen.
#86
Gispelmob
geschrieben 08. September 2019 - 11:47
Um einen Datenträger zu defragmentieren muss man zwangsläufig Daten lesen und schreiben. Das klappt nicht durch bloses anschauen.
Dieser Beitrag wurde von Gispelmob bearbeitet: 08. September 2019 - 11:47
AMD Ryzen 9 5950X, Asus ROG Strix X570-F Gaming, 32GB Corsair DDR4-3200, Asus Geforce GTX 3060 12GB, Creative Sound Blaster AE-7, 240GB SSD, 500GB SSD, 3x 1TB SSD, Win11 Home, 4x Acer G246HL Bbid, Logitech MX518 Gaming Mouse, Logitech G440 Mousepad, Logitech K120 Keyboard, Razer Tiamat 7.1 V2 Headset, Creative Inspire 5.1 5300 Soundsystem
#87
RalphS
- Gruppe: VIP Mitglieder
- Beiträge: 8.902
- Beigetreten: 20. Juli 07
- Reputation: 1.126
- Geschlecht:Männlich
- Wohnort:Zuhause
- Interessen:Ja
geschrieben 08. September 2019 - 15:03
Naja, es gibt schon Kolateral bei SSDs, bedingt durch die Zelltiefe / Schreibblockgröße. Block schreiben heißt Inhalt des Blocks lesen, neuen Inhalt migrieren, Resultat schreiben. Daß das nicht recht funktioniert wissen wir schon deswegen, daß es TRIM überhaupt gibt -- das ist exakt diesem Problem geschuldet, wirkt aber halt auch nur für gelöschte Daten.
Was bleibt sind Tests über einen gewissen Zeitraum. Gibt's Performancegewinne im Schnitt?
Plus, das ganze Problem löst sich sozusagen in Luft auf, wenn man mit seiner Platte auch arbeitet. Da Software eh keinen Zugriff auf die SSD (intern) hat, kann man denselben Effekt auch erzielen, indem man seine Datei einfach kopiert, das Original löscht und hinterher TRIM sagt.
Das Problem ist ebenfalls "keins", wenn genügend Platz frei ist. SSD > 90% zugemüllt? Dann wird es langsam, das gilt aber genauso für Festplatten und während der Grund technisch ein anderer ist, so ist es praktisch doch exakt dasselbe.
Daher (denk ich) genügt es wenn man sich wie bisher an das Credo hält, möglichst groß kaufen, möglichst 50% freihalten.
Rein von der Sache her würde ich sogar soweit gehen: es reicht, wenn man
-A- ein komplettes Backup von der SSD zieht
-B- die SSD leerputzt (und TRIM hinterherschiebt)
-C- das Backup zurückspielt.
Mehr kann Optimierungssoftware auch nicht machen, wenn man mal davon absieht, daß sie ggfs. den Datenstrom vorm Schreiben noch umformen kann. Aber das macht man bei File Restore auch --- daß man sektorbasiert auf SSD nicht schreiben soll hängt exakt mit demselben Problem zusammen, was O&O lösen möchte.
Was bleibt sind Tests über einen gewissen Zeitraum. Gibt's Performancegewinne im Schnitt?
Plus, das ganze Problem löst sich sozusagen in Luft auf, wenn man mit seiner Platte auch arbeitet. Da Software eh keinen Zugriff auf die SSD (intern) hat, kann man denselben Effekt auch erzielen, indem man seine Datei einfach kopiert, das Original löscht und hinterher TRIM sagt.
Das Problem ist ebenfalls "keins", wenn genügend Platz frei ist. SSD > 90% zugemüllt? Dann wird es langsam, das gilt aber genauso für Festplatten und während der Grund technisch ein anderer ist, so ist es praktisch doch exakt dasselbe.
Daher (denk ich) genügt es wenn man sich wie bisher an das Credo hält, möglichst groß kaufen, möglichst 50% freihalten.
Rein von der Sache her würde ich sogar soweit gehen: es reicht, wenn man
-A- ein komplettes Backup von der SSD zieht
-B- die SSD leerputzt (und TRIM hinterherschiebt)
-C- das Backup zurückspielt.
Mehr kann Optimierungssoftware auch nicht machen, wenn man mal davon absieht, daß sie ggfs. den Datenstrom vorm Schreiben noch umformen kann. Aber das macht man bei File Restore auch --- daß man sektorbasiert auf SSD nicht schreiben soll hängt exakt mit demselben Problem zusammen, was O&O lösen möchte.
"If you give a man a fish he is hungry again in an hour. If you teach him to catch a fish you do him a good turn."-- Anne Isabella Thackeray Ritchie
#88
X0XFanaticX0X
- Gruppe: Mitglieder
- Beiträge: 17
- Beigetreten: 24. Dezember 17
- Reputation: 0
- Geschlecht:Männlich
- Wohnort:Nordrhein-Westfalen
- Interessen:PC, NAS, Cloud
geschrieben 07. Januar 2020 - 22:07
O&O Defrag 23 verbreitet diese Nachricht.
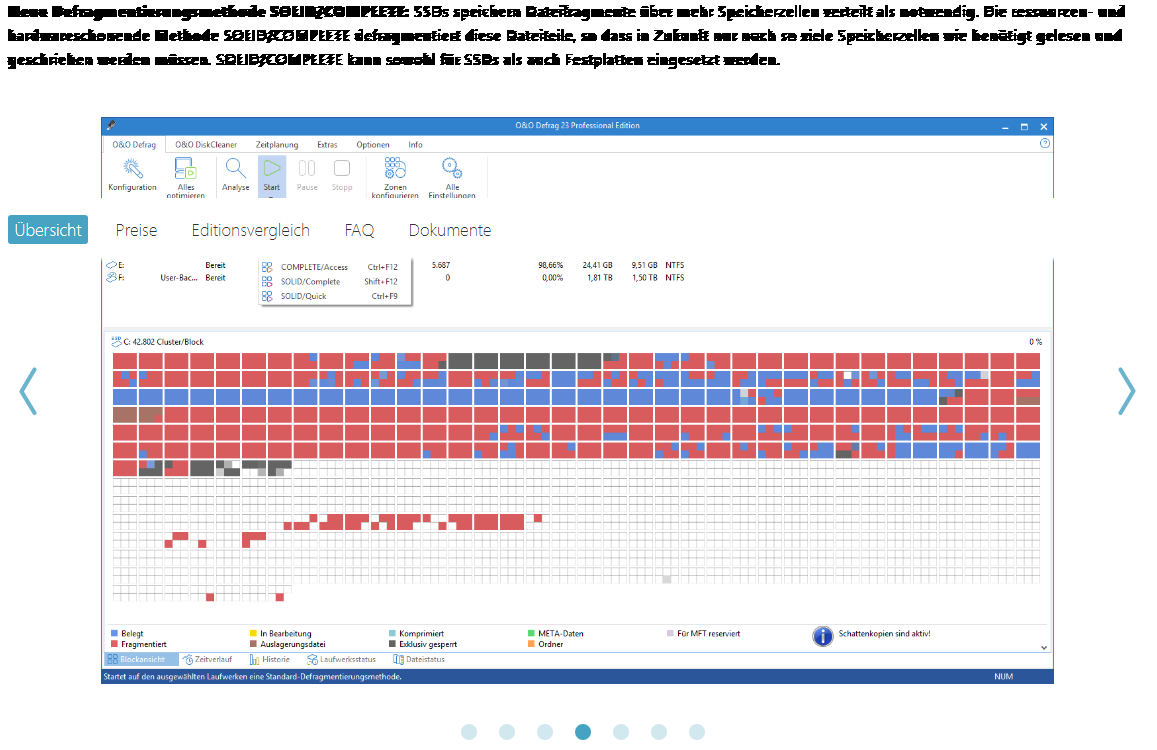
Therm. CoreX71 <3 | Windows-User since Windows 98
#89
Menfisk

- Gruppe: aktive Mitglieder
- Beiträge: 413
- Beigetreten: 25. Dezember 19
- Reputation: 39
- Geschlecht:Männlich
- Wohnort:Wasser
geschrieben 16. Februar 2020 - 11:03
Solange meine Intel SSD Toolbox sagt nicht defragmentieren,
werd ich einen Teufel tun.
werd ich einen Teufel tun.
#90
Stefan_der_held
- Gruppe: Offizieller Support
- Beiträge: 14.344
- Beigetreten: 08. April 06
- Reputation: 888
- Geschlecht:Männlich
- Wohnort:Dortmund NRW
- Interessen:Alles wo irgendwie Strom durchfließt fasziniert mich einfach weswegen ich halt Elektroinstallateur geworden bin :)
geschrieben 16. Februar 2020 - 11:56
Zitat (X0XFanaticX0X: 07. Januar 2020 - 22:07)
O&O Defrag 23 verbreitet diese Nachricht.
[...]
[...]
Ist klar... jeder will sein eigenes "Schlangen-Öl" verkaufen



