 Hilfe
Hilfe

 Neues Thema
Neues Thema
Hab ich gleich beim ersten Wort
»expected unqualified-id before 'public'
Smalltalk Guten Morgen, Guten Tag, Guten Abend Kaffeeklatsch
#177031
 Holger_N
Holger_N 
- Gruppe: aktive Mitglieder
- Beiträge: 5.170
- Beigetreten: 11. September 10
- Reputation: 458
- Geschlecht:Männlich
geschrieben 19. Juni 2017 - 22:32
Bauernregel: Regnets mächtig im April, passiert irgendwas, was sich auf April reimt.
#177032
RalphS

- Gruppe: VIP Mitglieder
- Beiträge: 8.902
- Beigetreten: 20. Juli 07
- Reputation: 1.126
- Geschlecht:Männlich
- Wohnort:Zuhause
- Interessen:Ja
geschrieben 19. Juni 2017 - 23:00
Da fehlt's mir bei Qt und C++, zugegeben. 
"If you give a man a fish he is hungry again in an hour. If you teach him to catch a fish you do him a good turn."-- Anne Isabella Thackeray Ritchie


#177033
Holger_N
- Gruppe: aktive Mitglieder
- Beiträge: 5.170
- Beigetreten: 11. September 10
- Reputation: 458
- Geschlecht:Männlich
geschrieben 20. Juni 2017 - 00:12
Daa daaaa da daa daa daaaaa daaaaa daaaaa
So und jetzt guck ich mir als Nächstes den ganzen formellen Kladderadatsch mit dem ordnungsgemäßen Zerstören am Ende an und danach kann die Bastelei losgehen.
So und jetzt guck ich mir als Nächstes den ganzen formellen Kladderadatsch mit dem ordnungsgemäßen Zerstören am Ende an und danach kann die Bastelei losgehen.
Dieser Beitrag wurde von Holger_N bearbeitet: 20. Juni 2017 - 00:19
Bauernregel: Regnets mächtig im April, passiert irgendwas, was sich auf April reimt.
#177034
RalphS
- Gruppe: VIP Mitglieder
- Beiträge: 8.902
- Beigetreten: 20. Juli 07
- Reputation: 1.126
- Geschlecht:Männlich
- Wohnort:Zuhause
- Interessen:Ja
geschrieben 20. Juni 2017 - 03:17
Mh? Wird der Knopp da automatisch in die Mitte gesetzt, oder wie läuft das? 
"If you give a man a fish he is hungry again in an hour. If you teach him to catch a fish you do him a good turn."-- Anne Isabella Thackeray Ritchie
#177035
Holger_N
- Gruppe: aktive Mitglieder
- Beiträge: 5.170
- Beigetreten: 11. September 10
- Reputation: 458
- Geschlecht:Männlich
geschrieben 20. Juni 2017 - 07:04
Nee das Fenster mit dem Knopf ist in der Hauptdatei und das Draufdrücken löst das Ereignis in meiner Klasse aus. Da wird nur per qDebug() die Variable ausgegeben, praktisch als Indikator, dass die Funktion dort überhaupt aufgerufen wird. Das war ja mein Hauptproblem. Jetzt was zu Basteln, dass was richtiges passiert ist ja nicht mehr das Problem. Hab da mal jetzt den Quatsch mit dem Knopf rausgeschmissen und einfach nur ein Label gebastelt, dem ich meine Eigenschaften zuordne. Darauf kann ich ja jetzt aufbauen. Dieses »Gerüst« ist ja das, was ich bislang nicht funktionierend hinbekommen habe.
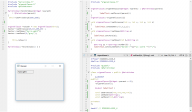
Damit könnte ich mir ja jetzt zum Beispiel ein Label basteln, dass meine bevorzugten Eigenschaften schon von Natur aus enthält bzw. Sachen Konstruieren, die es so noch nicht gibt, so wie die Tabelle aus Labeln (nur als Beispiel) wo ja mein Problem nicht der eigentlich Code für die Tabelle selbst ist, sondern eben das Aufrufen der Klasse, was ja nun geht. Ich weiß zwar immernoch nicht, was daran jetzt eine Klasse ist (von der Wortbedeutung her) aber solange das funktioniert ist mir das egal.
Da ist jetzt programmiertechnisch bestimmt noch ein Haufen Murks bei aber ich weiß jetzt, wo ich weitermachen kann.
Damit könnte ich mir ja jetzt zum Beispiel ein Label basteln, dass meine bevorzugten Eigenschaften schon von Natur aus enthält bzw. Sachen Konstruieren, die es so noch nicht gibt, so wie die Tabelle aus Labeln (nur als Beispiel) wo ja mein Problem nicht der eigentlich Code für die Tabelle selbst ist, sondern eben das Aufrufen der Klasse, was ja nun geht. Ich weiß zwar immernoch nicht, was daran jetzt eine Klasse ist (von der Wortbedeutung her) aber solange das funktioniert ist mir das egal.
Da ist jetzt programmiertechnisch bestimmt noch ein Haufen Murks bei aber ich weiß jetzt, wo ich weitermachen kann.
Dieser Beitrag wurde von Holger_N bearbeitet: 20. Juni 2017 - 07:24
Bauernregel: Regnets mächtig im April, passiert irgendwas, was sich auf April reimt.
#177036
Holger_N
- Gruppe: aktive Mitglieder
- Beiträge: 5.170
- Beigetreten: 11. September 10
- Reputation: 458
- Geschlecht:Männlich
geschrieben 20. Juni 2017 - 12:24
Mist, funktioniert doch nicht ganz so, wie ich mir das vorgestellt hatte. Die ganzen Werte, die in den Methoden »ankommen«, kann man in der richtigen Klasse gar nicht verwenden, also da, wo man die ja eigentlich braucht.
Bauernregel: Regnets mächtig im April, passiert irgendwas, was sich auf April reimt.
#177037
RalphS
- Gruppe: VIP Mitglieder
- Beiträge: 8.902
- Beigetreten: 20. Juli 07
- Reputation: 1.126
- Geschlecht:Männlich
- Wohnort:Zuhause
- Interessen:Ja
geschrieben 20. Juni 2017 - 13:18
Was ich meinte war die Positionierung von dem Knopp. Da gibt es ein setGeometry(), aber da geht für mich grad nicht draus hervor, ob das die Knoppgröße festlegt (breit+hoch) oder ob das auch was mit der Anordnung im Fenster zu tun hat. Sonst ist da ja nix.
Klasse = Bauanleitung. Wie bei Ikea der Zettel. Den kann man einmal haben und, wenn man genug Holz und Schrauben hat, beliebig viele Betten draus zimmern. Das sind dann die Objekte bzw die Instanzen der Klasse.
class Bett {} schreibt also den Anleitungszettel.
Und new Bett() baut das Bett mit Hilfe dieses Zettels.
Klasse = Bauanleitung. Wie bei Ikea der Zettel. Den kann man einmal haben und, wenn man genug Holz und Schrauben hat, beliebig viele Betten draus zimmern. Das sind dann die Objekte bzw die Instanzen der Klasse.
class Bett {} schreibt also den Anleitungszettel.
Und new Bett() baut das Bett mit Hilfe dieses Zettels.
"If you give a man a fish he is hungry again in an hour. If you teach him to catch a fish you do him a good turn."-- Anne Isabella Thackeray Ritchie
#177038
Holger_N
- Gruppe: aktive Mitglieder
- Beiträge: 5.170
- Beigetreten: 11. September 10
- Reputation: 458
- Geschlecht:Männlich
geschrieben 20. Juni 2017 - 13:48
Ja ich habe da eine Lösung gefunden. Ich habe noch eine Methode »bauen« am Schluß eingebaut, da sind alle Werte da.
Bei der Knopf-Variante war da nichts weiter drin, da ging es nur um die Verbindung, weil ich die Klasse ja gleich in eine extra Datei gesteckt habe, aber nun Finale. (Ohne das ich das brauchte, aber weil es nun schonmal mein Erklärbeispiel war:
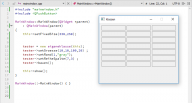
Mit der »Bauanleitung« (Das ist jetzt schon die für das untere Bild, hab ja inzwischen weitergebastelt.)
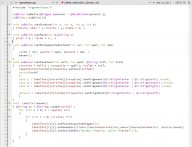
Und da hatte ich so meine Probleme mit den Variablen. Macht man das so oder habe ich da zu umständlich gedacht. Also ich meine nicht den Schleifencode, der die Tabelle baut. Da gibts ja immer 80 Wege nach Rom, sondern so den Aufbau mit der Anordnung der Methoden.
Ich muß mich langsam mal bremsen. jetzt will ich das Probeding schon gar nicht mehr löschen, vielleicht brauche ich das mal. So doof war die Idee gar nicht. Das mit dem extra »bauen()« Aufruf habe ich auch noch weggekriegt. Letztendlich hat es zwar wieder Nerven gekostet aber jetzt sind wieder ein paar Sachen mehr doch logisch.
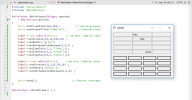
Bei der Knopf-Variante war da nichts weiter drin, da ging es nur um die Verbindung, weil ich die Klasse ja gleich in eine extra Datei gesteckt habe, aber nun Finale. (Ohne das ich das brauchte, aber weil es nun schonmal mein Erklärbeispiel war:
Mit der »Bauanleitung« (Das ist jetzt schon die für das untere Bild, hab ja inzwischen weitergebastelt.)
Und da hatte ich so meine Probleme mit den Variablen. Macht man das so oder habe ich da zu umständlich gedacht. Also ich meine nicht den Schleifencode, der die Tabelle baut. Da gibts ja immer 80 Wege nach Rom, sondern so den Aufbau mit der Anordnung der Methoden.
Ich muß mich langsam mal bremsen. jetzt will ich das Probeding schon gar nicht mehr löschen, vielleicht brauche ich das mal. So doof war die Idee gar nicht. Das mit dem extra »bauen()« Aufruf habe ich auch noch weggekriegt. Letztendlich hat es zwar wieder Nerven gekostet aber jetzt sind wieder ein paar Sachen mehr doch logisch.
Dieser Beitrag wurde von Holger_N bearbeitet: 20. Juni 2017 - 17:23
Bauernregel: Regnets mächtig im April, passiert irgendwas, was sich auf April reimt.
#177039
Holger_N
- Gruppe: aktive Mitglieder
- Beiträge: 5.170
- Beigetreten: 11. September 10
- Reputation: 458
- Geschlecht:Männlich
geschrieben 22. Juni 2017 - 19:55
Verrückt, jetzt hatte ich eine Frage zu SQL-Queries und während meiner Recherche, wie ich die Frage möglichst fachgerecht formuliere, habe ich mir die selber beantwortet. Ich mache die Abfragen ohne JOIN. Nur mein Fremdschlüssel funktioniert nicht richtig. Das frage ich aber mal im richtigen Forum statt im Smalltalk. Ach nee, das scheint was Qt-spezifisches zu sein. Da muß ich bestimmt nur irgendein Model includieren, das kriege ich vielleicht alleine raus.
Dieser Beitrag wurde von Holger_N bearbeitet: 22. Juni 2017 - 20:48
Bauernregel: Regnets mächtig im April, passiert irgendwas, was sich auf April reimt.
#177040
RalphS
- Gruppe: VIP Mitglieder
- Beiträge: 8.902
- Beigetreten: 20. Juli 07
- Reputation: 1.126
- Geschlecht:Männlich
- Wohnort:Zuhause
- Interessen:Ja
geschrieben 22. Juni 2017 - 22:32
.... hä?
Du hast ne SQL-Abfrage. Die kommt ohne JOIN aus. Und der Fremdschlüssel funktioniert nicht richtig.

Sorry. Versteh nicht, was das Problem sein könnte.
Ansonsten, Datenbankabfragen sind natürlich kein Qt-Problem; zum Qt-Problem wird es erst, wenn die Datensätze erfolgreich abgefragt und nun nur noch dargestellt werden müssen.
Du hast ne SQL-Abfrage. Die kommt ohne JOIN aus. Und der Fremdschlüssel funktioniert nicht richtig.
Sorry. Versteh nicht, was das Problem sein könnte.
Ansonsten, Datenbankabfragen sind natürlich kein Qt-Problem; zum Qt-Problem wird es erst, wenn die Datensätze erfolgreich abgefragt und nun nur noch dargestellt werden müssen.
"If you give a man a fish he is hungry again in an hour. If you teach him to catch a fish you do him a good turn."-- Anne Isabella Thackeray Ritchie
#177041
Holger_N
- Gruppe: aktive Mitglieder
- Beiträge: 5.170
- Beigetreten: 11. September 10
- Reputation: 458
- Geschlecht:Männlich
geschrieben 23. Juni 2017 - 01:36
Das sind zwei Sachen unabhängig voneinander.
Ich hatte eine Abfrage vom Schema her:
SELECT a,b
FROM c,d
WHERE c.spalte = d.id
die Entsprechung mit JOIN wäre sowas wie
SELECT a, b
FROM c
FULL INNER JOIN d
ON c.spalte = d.id
So und das war bei 200.000 Datensätzen noch gleich schnell. Wobei ich LEFT JOIN verwendete, was in meinem Fall das gleiche Ergebnis bringt, weil es in beiden Spalten keine Werte gibt die ausgeschlossen wären mit LEFT, RIGHT oder INNER JOIN. Ich wollte eigentlich wissen, was von den Varianten zu bevorzugen ist, konnte mir die Frage aber beantworten. mit LEFT, RIGHT und INNER ließen sich ja Datensätze ausschließen, falls es links, rechts oder links oder beidseitig Werte gäbe, die zur anderen Seite nicht passen.
So und dann habe ich festgestellt, dass FULL INNER JOIN bei SQLite gar nicht geht, womit sich die Frage ja erübrigt. Dann nehme ich die JOIN Variante, wenn ich mit den Bedinungen arbeiten will, die LEFT, RIGHT und INNER bieten und die Variante ohne JOIN nehme ich, wenn ich diese Bedingungen sicher ausschließen will.
Das war eine Sache
###################################################################################################
Die zweite ist ein Problem dass damit zwar zusammenhängt aber es ist sozusagen eigenständig.
Ich hatte einen Fremdschlüssel gesetzt (ich mach mal ein allgemeines Beispiel):
eine Tabelle »gruppe« mit id und Gruppennamen und eine Tabelle »gruppenmitglieder« mit id, gruppen_id, mitgliedsname
nun hatte ich einen Fremdschlüssel von der spalte gruppen_id auf die id der Tabelle »gruppe« (mit CASCADE wen DELETE)
Nun konnte ich eine Gruppe in der Gruppentabelle löschen und automatisch wurden in der Mitgliedertabelle alle Mitglieder dieser Gruppe auch gelöscht. Das funktioniert aber nur, wenn ich den im SQLiteStudio die Gruppe lösche. Wenn ich das aus meiner Anwendung mache, wird nur die Gruppe gelöscht und die Mitglieder bleiben. Nun nehme ich an, das ist irgendsoein Qt-Ding. Da muß man doch immer so Sachen includieren, damit am Ende auch alles funktioniert und da fehlt vielleicht nur ein #include "QSql/QSqldenk_an_den_Fremdschluessel.h" oder so. Da forsche ich noch alleine ein bißchen.
####################################################################################################
Hab aber schon wieder das nächste Problem. Ich habe nun auch geschafft, statt mit einer SQLite Datenbank, auch eine Variante mit einer Access-Datenbank hinzukriegen. Allerdings sind da die Queries minimal anders. Im Moment kriege ich keine Werte ein AUTOINCREMENT Feld. Bei SQLite ging das mit
INSERT INTO tabelle (id, …) VALUES (NULL,…) ;
aber eine ACCESS-Tabelle wehrt sich gegen NULL und auch gegen '' .
-------------------------------------------
Ich glaube es geht mit ganz Wegglassen - Nochmal testen - HURRA - Jawoll geht.
Ich hatte eine Abfrage vom Schema her:
SELECT a,b
FROM c,d
WHERE c.spalte = d.id
die Entsprechung mit JOIN wäre sowas wie
SELECT a, b
FROM c
FULL INNER JOIN d
ON c.spalte = d.id
So und das war bei 200.000 Datensätzen noch gleich schnell. Wobei ich LEFT JOIN verwendete, was in meinem Fall das gleiche Ergebnis bringt, weil es in beiden Spalten keine Werte gibt die ausgeschlossen wären mit LEFT, RIGHT oder INNER JOIN. Ich wollte eigentlich wissen, was von den Varianten zu bevorzugen ist, konnte mir die Frage aber beantworten. mit LEFT, RIGHT und INNER ließen sich ja Datensätze ausschließen, falls es links, rechts oder links oder beidseitig Werte gäbe, die zur anderen Seite nicht passen.
So und dann habe ich festgestellt, dass FULL INNER JOIN bei SQLite gar nicht geht, womit sich die Frage ja erübrigt. Dann nehme ich die JOIN Variante, wenn ich mit den Bedinungen arbeiten will, die LEFT, RIGHT und INNER bieten und die Variante ohne JOIN nehme ich, wenn ich diese Bedingungen sicher ausschließen will.
Das war eine Sache
###################################################################################################
Die zweite ist ein Problem dass damit zwar zusammenhängt aber es ist sozusagen eigenständig.
Ich hatte einen Fremdschlüssel gesetzt (ich mach mal ein allgemeines Beispiel):
eine Tabelle »gruppe« mit id und Gruppennamen und eine Tabelle »gruppenmitglieder« mit id, gruppen_id, mitgliedsname
nun hatte ich einen Fremdschlüssel von der spalte gruppen_id auf die id der Tabelle »gruppe« (mit CASCADE wen DELETE)
Nun konnte ich eine Gruppe in der Gruppentabelle löschen und automatisch wurden in der Mitgliedertabelle alle Mitglieder dieser Gruppe auch gelöscht. Das funktioniert aber nur, wenn ich den im SQLiteStudio die Gruppe lösche. Wenn ich das aus meiner Anwendung mache, wird nur die Gruppe gelöscht und die Mitglieder bleiben. Nun nehme ich an, das ist irgendsoein Qt-Ding. Da muß man doch immer so Sachen includieren, damit am Ende auch alles funktioniert und da fehlt vielleicht nur ein #include "QSql/QSqldenk_an_den_Fremdschluessel.h" oder so. Da forsche ich noch alleine ein bißchen.
####################################################################################################
Hab aber schon wieder das nächste Problem. Ich habe nun auch geschafft, statt mit einer SQLite Datenbank, auch eine Variante mit einer Access-Datenbank hinzukriegen. Allerdings sind da die Queries minimal anders. Im Moment kriege ich keine Werte ein AUTOINCREMENT Feld. Bei SQLite ging das mit
INSERT INTO tabelle (id, …) VALUES (NULL,…) ;
aber eine ACCESS-Tabelle wehrt sich gegen NULL und auch gegen '' .
-------------------------------------------
Ich glaube es geht mit ganz Wegglassen - Nochmal testen - HURRA - Jawoll geht.
Dieser Beitrag wurde von Holger_N bearbeitet: 23. Juni 2017 - 01:53
Bauernregel: Regnets mächtig im April, passiert irgendwas, was sich auf April reimt.
#177042
RalphS
- Gruppe: VIP Mitglieder
- Beiträge: 8.902
- Beigetreten: 20. Juli 07
- Reputation: 1.126
- Geschlecht:Männlich
- Wohnort:Zuhause
- Interessen:Ja
geschrieben 23. Juni 2017 - 04:46
JOINS:
Es gibt die alte Syntax von vor 92. Das ist formal eine Art CROSS JOIN, aber mit Einschränkungen. Sollte man nicht machen, weil wenn man die Einschränkung vergißt, bekommt man spatiale Ergebnisse (cf Vektorprodukt). Fünf Tabellen verkommat und keien Bedingung? Es wird ein fünfdimensionaler Raum erstellt mit jeder Tabelle als Dimension und man kriegt alle(!) möglichen Raumkoordinaten zurück, die irgendwie machbar sind. Für fünf Tabellen mit jeweils 10 Datensätzen sind das also 10*10*10*10*10.
Schlecht. Nimm die JOIN-Syntax.
Joins sind einfach Zuordnungen. Wie, kann man sich aussuchen mit INNER und OUTER, bzw noch anderen "Optimierungen".
Man kann das imo am besten geometrisch, oder vielleicht mengenmäßig, verstehen.
Wenn ich eine Tabelle A hab und eien Tabelle B, dann ist ein JOIN die ungeordnete Kombination (A, B).
Ohne weitere Bedingung ist das der erwähnte CROSS JOIN, das vollständige Kreuzprodukt aus beiden.
Mit Bedingung kann man den geometrischen Raum aber einschränken. Wenn wir also zwei Ebenen im Raum haben und ich will die Schnittmenge haben, dann definier ich das mit der JOIN-Bedingung und sage, ich will nur die Werte haben, wo Tabelle A und Tabelle B mit Eigenschaft X zusammenpassen. Normalerweise der Primär/Fremdschlüssel. Aber das ist keine Bedingung.
Und so kriegen wir für zwei Tabellen mit den Einträgen
#|A|B
a|1|3
b|2|4
c|3|5
als JOIN-Bedingung Folgendes raus:
- Inner Join.
=> Nur die Werte, die in beiden Tabellen übereinstimmen. Hier 3. Man kriegt also als Paar (Ac, Ba) zurück. Ergebnismenge = 1 Datensatz. Das ist der Standard-JOIN, wenn man nix anderes hinschreibt. A JOIN B und A INNER JOIN B sind identisch, ebenso wie A JOIN B und B JOIN A.
- OUTER Joins.
- LEFT Join.
Man nimmt alle Werte aus der LINKEN Tabelle und fügt die passenden Werte der rechten Tabelle an. Also 1,2,3 von A und dort ordnet man dann die von B zu. Übereinstimmen tut nur der Wert 3 (Tabelle B, Datensatz a). Die anderen kriegen NULLen (nicht die Zahl, sondern "unbekannt"). Ergo gibt es hier drei Ergebnisdatensätze (Aa, NULL), (Ab, NULL) und (Ac, Ba).
- RIGHT JOIN. Dasselbe, aber andersherum, von RECHTS angefangen.
Ergbnismenge also wieder drei Datensätze, diesmal aber (Ba, Ac), (Bb, NULL) und (Bc, NULL).
- FULL JOIN. LEFT+RIGHT zusammengenommen. Also fünf Datensätze: (Aa, NULL), (Ab, NULL), (Ac, Ba), (NULL, Bb) und (NULL, Bc).
- Inner Joins ist damit der "Kern" der Ergebnismenge und Outer (Left, Right, Full) das Außenherum.
- Und der CROSS JOIN hat 9 Einträge (jeweils drei, also 3x3):
FULL INNER gibt es so nicht, da es hier egal ist, wo man anfängt.
INNER JOINs sind außerdem schneller als OUTER JOINs und LEFTs sind üblicherweise performanter als RIGHTs, weswegen man letztere nur dann verwenden sollte, wenn man das nicht in einen LEFT umbiegen kann (zB wegen A LEFT JOIN B RIGHT JOIN C). Abgearbeitet wird von links, sodaß in diesem Beispiel zuerst A LEFT JOIN B ermittelt wird und dann C hergenommen wird und die Ergebnisse aus dem JOIN von eben dort dann drangelegt werden.
Weitere JOINs gibt's auch, als Sonderformen oder Spezialfälle. A und B müssen nicht verschieden sein: sind sie gleich, hat man einen SELF JOIN, der aber nicht als solcher ausgewiesen ist. Einfach A JOIN A.
NATURAL JOINs schließlich sind eine Vereinfachung, wenn auch potentiell gefährliche. Natural Joins gehen davon aus, daß gleichnamige Spalten die JOIN-Bedingung darstellen. A NATURAL JOIN B funktioniert also ohne explizite Bedingung, hat aber den Haken, daß wenn man zB eine Spalte A.id hat und eine Spalte B.id, und die haben nix miteinander zu tun, naja dann kommt für den NATURAL JOIN auch nix Gescheites raus. Und wenn es mehr als nur eine gleichnamige Spalte gibt, wird es eh interessant.
Und, ja. Join-Bedingungen können mehrteilig sein. Das hat Vorteile, wenn man nur eine Untermenge vom gesamten JOIN braucht, der dann nämlich nicht mehr komplett zusammengezimmert werden muß. A JOIN B on (A.id=B.id AND A.id=2) ist vielleicht ein bissel doof aussehendes Beispiel, sorgt aber dafür, daß der JOIN nur Datensätze mit A.ID = B.ID = 2 zurückliefert; hätte man das in den WHERE-Teil gestopft, wäre der JOIN vollständig(er) gewesen und man hätte die überzähligen Datensätze wieder wegwerfen müssen.
Default-Werte kann man immer weglassen. Das gilt für Autoincrement (wird der nächste eingetragen) für DEFAULTs (was auch immer als DEFAULT festgelegt wurde) und für Spalten, die NULL zulassen auch (da landet entsprechend NULL drin). Die einzige Situation wo das nicht geht ist, wenn man NOT NULL definiert hat und keinen DEFAULT oder AUTOINCREMENT gesetzt hat. Denn dann würde "versucht", NULL zu setzen und das ist aber verboten per definitionem. Also gibt es den Fehler.
Das mit den Schlüsseln irritiert. Aber wenn ich mich recht entsinne, mußte bzw konnte man SQLITE noch mit .pragma XYZ Direktiven steuern. Müßtest Du mal in der SQLite-Doku schauen. Mit Qt sollte das nix zu tun haben, kann aber sein, daß da irgendwelche pragmas standardmäßig gesetzt oder nicht gesetzt sind (kann auch das Studio so handhaben).
Es gibt die alte Syntax von vor 92. Das ist formal eine Art CROSS JOIN, aber mit Einschränkungen. Sollte man nicht machen, weil wenn man die Einschränkung vergißt, bekommt man spatiale Ergebnisse (cf Vektorprodukt). Fünf Tabellen verkommat und keien Bedingung? Es wird ein fünfdimensionaler Raum erstellt mit jeder Tabelle als Dimension und man kriegt alle(!) möglichen Raumkoordinaten zurück, die irgendwie machbar sind. Für fünf Tabellen mit jeweils 10 Datensätzen sind das also 10*10*10*10*10.
Schlecht. Nimm die JOIN-Syntax.
Joins sind einfach Zuordnungen. Wie, kann man sich aussuchen mit INNER und OUTER, bzw noch anderen "Optimierungen".
Man kann das imo am besten geometrisch, oder vielleicht mengenmäßig, verstehen.
Wenn ich eine Tabelle A hab und eien Tabelle B, dann ist ein JOIN die ungeordnete Kombination (A, B).
Ohne weitere Bedingung ist das der erwähnte CROSS JOIN, das vollständige Kreuzprodukt aus beiden.
Mit Bedingung kann man den geometrischen Raum aber einschränken. Wenn wir also zwei Ebenen im Raum haben und ich will die Schnittmenge haben, dann definier ich das mit der JOIN-Bedingung und sage, ich will nur die Werte haben, wo Tabelle A und Tabelle B mit Eigenschaft X zusammenpassen. Normalerweise der Primär/Fremdschlüssel. Aber das ist keine Bedingung.
Und so kriegen wir für zwei Tabellen mit den Einträgen
#|A|B
a|1|3
b|2|4
c|3|5
als JOIN-Bedingung Folgendes raus:
- Inner Join.
=> Nur die Werte, die in beiden Tabellen übereinstimmen. Hier 3. Man kriegt also als Paar (Ac, Ba) zurück. Ergebnismenge = 1 Datensatz. Das ist der Standard-JOIN, wenn man nix anderes hinschreibt. A JOIN B und A INNER JOIN B sind identisch, ebenso wie A JOIN B und B JOIN A.
- OUTER Joins.
- LEFT Join.
Man nimmt alle Werte aus der LINKEN Tabelle und fügt die passenden Werte der rechten Tabelle an. Also 1,2,3 von A und dort ordnet man dann die von B zu. Übereinstimmen tut nur der Wert 3 (Tabelle B, Datensatz a). Die anderen kriegen NULLen (nicht die Zahl, sondern "unbekannt"). Ergo gibt es hier drei Ergebnisdatensätze (Aa, NULL), (Ab, NULL) und (Ac, Ba).
- RIGHT JOIN. Dasselbe, aber andersherum, von RECHTS angefangen.
Ergbnismenge also wieder drei Datensätze, diesmal aber (Ba, Ac), (Bb, NULL) und (Bc, NULL).
- FULL JOIN. LEFT+RIGHT zusammengenommen. Also fünf Datensätze: (Aa, NULL), (Ab, NULL), (Ac, Ba), (NULL, Bb) und (NULL, Bc).
- Inner Joins ist damit der "Kern" der Ergebnismenge und Outer (Left, Right, Full) das Außenherum.
- Und der CROSS JOIN hat 9 Einträge (jeweils drei, also 3x3):
╔════╤════╗ ║ A │ B ║ ╟────┼────╢ ║ 1 │ 3 ║ ║ 1 │ 4 ║ ║ 1 │ 5 ║ ║ 2 │ 3 ║ ║ 2 │ 4 ║ ║ 2 │ 5 ║ ║ 3 │ 3 ║ ║ 3 │ 4 ║ ║ 3 │ 5 ║ ╚════╧════╝
FULL INNER gibt es so nicht, da es hier egal ist, wo man anfängt.
INNER JOINs sind außerdem schneller als OUTER JOINs und LEFTs sind üblicherweise performanter als RIGHTs, weswegen man letztere nur dann verwenden sollte, wenn man das nicht in einen LEFT umbiegen kann (zB wegen A LEFT JOIN B RIGHT JOIN C). Abgearbeitet wird von links, sodaß in diesem Beispiel zuerst A LEFT JOIN B ermittelt wird und dann C hergenommen wird und die Ergebnisse aus dem JOIN von eben dort dann drangelegt werden.
Weitere JOINs gibt's auch, als Sonderformen oder Spezialfälle. A und B müssen nicht verschieden sein: sind sie gleich, hat man einen SELF JOIN, der aber nicht als solcher ausgewiesen ist. Einfach A JOIN A.
NATURAL JOINs schließlich sind eine Vereinfachung, wenn auch potentiell gefährliche. Natural Joins gehen davon aus, daß gleichnamige Spalten die JOIN-Bedingung darstellen. A NATURAL JOIN B funktioniert also ohne explizite Bedingung, hat aber den Haken, daß wenn man zB eine Spalte A.id hat und eine Spalte B.id, und die haben nix miteinander zu tun, naja dann kommt für den NATURAL JOIN auch nix Gescheites raus. Und wenn es mehr als nur eine gleichnamige Spalte gibt, wird es eh interessant.
Und, ja. Join-Bedingungen können mehrteilig sein. Das hat Vorteile, wenn man nur eine Untermenge vom gesamten JOIN braucht, der dann nämlich nicht mehr komplett zusammengezimmert werden muß. A JOIN B on (A.id=B.id AND A.id=2) ist vielleicht ein bissel doof aussehendes Beispiel, sorgt aber dafür, daß der JOIN nur Datensätze mit A.ID = B.ID = 2 zurückliefert; hätte man das in den WHERE-Teil gestopft, wäre der JOIN vollständig(er) gewesen und man hätte die überzähligen Datensätze wieder wegwerfen müssen.
Default-Werte kann man immer weglassen. Das gilt für Autoincrement (wird der nächste eingetragen) für DEFAULTs (was auch immer als DEFAULT festgelegt wurde) und für Spalten, die NULL zulassen auch (da landet entsprechend NULL drin). Die einzige Situation wo das nicht geht ist, wenn man NOT NULL definiert hat und keinen DEFAULT oder AUTOINCREMENT gesetzt hat. Denn dann würde "versucht", NULL zu setzen und das ist aber verboten per definitionem. Also gibt es den Fehler.
Das mit den Schlüsseln irritiert. Aber wenn ich mich recht entsinne, mußte bzw konnte man SQLITE noch mit .pragma XYZ Direktiven steuern. Müßtest Du mal in der SQLite-Doku schauen. Mit Qt sollte das nix zu tun haben, kann aber sein, daß da irgendwelche pragmas standardmäßig gesetzt oder nicht gesetzt sind (kann auch das Studio so handhaben).
Dieser Beitrag wurde von RalphS bearbeitet: 23. Juni 2017 - 04:50
"If you give a man a fish he is hungry again in an hour. If you teach him to catch a fish you do him a good turn."-- Anne Isabella Thackeray Ritchie
#177043
Holger_N
- Gruppe: aktive Mitglieder
- Beiträge: 5.170
- Beigetreten: 11. September 10
- Reputation: 458
- Geschlecht:Männlich
geschrieben 23. Juni 2017 - 08:35
Ja hatte das mit dem PRAGMA hatte ich probiert. Es funktioniert ja auch aber nur im SQLiteStudio, also auch in der Datenbank wo ich den Fremdschlüssel aus meiner Anwendung heraus setze funktioniert das, wenn ich diese Datei im SQLiteStudio öffne. Und andersrum, in der Datei, wo ich den Schlüssel per Studio setze, funktioniert die Sache nicht, wenn ich die Datei in meiner Anwendung öffne. Was aber im Moment egal ist, da ich meine Anwendung von SQLite auf Access umbaue, also nur statt der SQLite DB eine .mdb Datei benutze. Da gibts gerade allerhand zu ändern. Statt "LIMIT 1" am Ende nun "SELECT TOP 1 * FROM
" da muß man erstmal drauf kommen. Die Meisten sind nur Winzigkeiten aber so fiese kleine Versteckte. Dem Compiler sind die ja egal, muß man alles probieren und dann suchen.
Mit den JOINS ist klar. Da hatte ich mich vielleicht doof ausgedrückt. Wenn es geht nehme ich JOINs und die Variante ohne JOINs, wo also dann wirklich alles erfasst wird, was zusammenhängt nehme ich nur dann, wenn ich das auch ganz bewußt so will, was auch immer dann der Grund dafür ist.
Mit den JOINS ist klar. Da hatte ich mich vielleicht doof ausgedrückt. Wenn es geht nehme ich JOINs und die Variante ohne JOINs, wo also dann wirklich alles erfasst wird, was zusammenhängt nehme ich nur dann, wenn ich das auch ganz bewußt so will, was auch immer dann der Grund dafür ist.
Bauernregel: Regnets mächtig im April, passiert irgendwas, was sich auf April reimt.
#177044
RalphS
- Gruppe: VIP Mitglieder
- Beiträge: 8.902
- Beigetreten: 20. Juli 07
- Reputation: 1.126
- Geschlecht:Männlich
- Wohnort:Zuhause
- Interessen:Ja
geschrieben 23. Juni 2017 - 12:17
Ja, das eine ist eher T-SQL (MS SQL) und das andere eher MySQL-style.
SQLite hat immer bissel so das Problem, daß es (noch) nicht 100%ig den SQL-Standard unterstützt.
So Dinge wie pragma foreign_keys(x) zum Bleistift. Das ist standardmäßig deaktiviert (x=0) und so werden keine Foreign Keys unterstützt, wenn man das nicht bewußt anstellt (mit x=1). Entsprechend kann aber derselbe Befehl das auch wieder ausmachen, nämlich mit der 0, und wenn man dann eine IDE hat, welche einfach solche Pragmas zur Initialisierung setzt, naja dann sind zwar die FKs in der Datenbank, aber das Verhalten, so wie Du ja schreibst, ist dann anwendungsspezifisch.
Auch wenn es das nicht sein sollte.
Dafür ist es in der Public Domain.
Access, mh, zu lang nicht mehr mit gearbeitet. Normal tät ich ja sagen, verwend doch einfach MS SQL als Express oder Developer-Edition im Backend; aber wenn Du das natürlich irgendwann mal verteilen willst an andere, dann ist da natürlich nicht notwendigerweise ein SQL-Server da.
Ach ja. MSJET (die Access-Laufzeit) gibts in zwei Versionen, "alt" und "neu", einmal JET4 (.mdb) von Win31 oder so und einmal ACE (.accdb) von Access 2007+. Die alte ist auf Windows-Systemen üblicherweise vorhanden (allerdings nicht bekannt, wie lange noch). Die neue nicht. Dafür ist aber die alte tatsächlich ein Urgestein. Die neue kann ggf .mdb und .accdb und man kann auch mehr machen damit, aber dafür muß dann irgendwie die Laufzeit auf den Zielcomputer, entweder per extra Download oder Deinem Paket mit beigelegt.
Nur so als FYI.
SQLite hat immer bissel so das Problem, daß es (noch) nicht 100%ig den SQL-Standard unterstützt.
So Dinge wie pragma foreign_keys(x) zum Bleistift. Das ist standardmäßig deaktiviert (x=0) und so werden keine Foreign Keys unterstützt, wenn man das nicht bewußt anstellt (mit x=1). Entsprechend kann aber derselbe Befehl das auch wieder ausmachen, nämlich mit der 0, und wenn man dann eine IDE hat, welche einfach solche Pragmas zur Initialisierung setzt, naja dann sind zwar die FKs in der Datenbank, aber das Verhalten, so wie Du ja schreibst, ist dann anwendungsspezifisch.
Auch wenn es das nicht sein sollte.
Dafür ist es in der Public Domain.
Access, mh, zu lang nicht mehr mit gearbeitet. Normal tät ich ja sagen, verwend doch einfach MS SQL als Express oder Developer-Edition im Backend; aber wenn Du das natürlich irgendwann mal verteilen willst an andere, dann ist da natürlich nicht notwendigerweise ein SQL-Server da.
Ach ja. MSJET (die Access-Laufzeit) gibts in zwei Versionen, "alt" und "neu", einmal JET4 (.mdb) von Win31 oder so und einmal ACE (.accdb) von Access 2007+. Die alte ist auf Windows-Systemen üblicherweise vorhanden (allerdings nicht bekannt, wie lange noch). Die neue nicht. Dafür ist aber die alte tatsächlich ein Urgestein. Die neue kann ggf .mdb und .accdb und man kann auch mehr machen damit, aber dafür muß dann irgendwie die Laufzeit auf den Zielcomputer, entweder per extra Download oder Deinem Paket mit beigelegt.
Nur so als FYI.
"If you give a man a fish he is hungry again in an hour. If you teach him to catch a fish you do him a good turn."-- Anne Isabella Thackeray Ritchie
#177045
Holger_N
- Gruppe: aktive Mitglieder
- Beiträge: 5.170
- Beigetreten: 11. September 10
- Reputation: 458
- Geschlecht:Männlich
geschrieben 23. Juni 2017 - 12:53
Es gab irgendwie zwei Versionen von den .mdb. eine bis 2000 und eine danach bis 2003 und danach die sind dann wohl .access aber bei den .access kriege ich einfach keine Verbindung hin.
Die sonstigen Fehler sind aber gar nicht mal so schlecht. Bei der Suche und Reparatur habe ich nochmal Einiges optimieren können. Was jetzt gerade nicht klappt ist dass Passwort. Also ich kann in Access ja ein Passwort vergeben aber ich finde keine Möglichkeit, das von meiner Anwendung aus zum Verbinden mitzugeben. Das muß ich noch finden, dann bin ich glücklich. Ein frontendseitiges PW habe ich ja drin, damit man sich bei der Anwendung anmelden muß, aber das hilft ja nix, wenn einer die Datei mopst oder die einfach mit Access öffnet.
Sprachs und auf einmal klappt es auch mit access. Dann baue ich nochmal um, von mdb auf access.
Die sonstigen Fehler sind aber gar nicht mal so schlecht. Bei der Suche und Reparatur habe ich nochmal Einiges optimieren können. Was jetzt gerade nicht klappt ist dass Passwort. Also ich kann in Access ja ein Passwort vergeben aber ich finde keine Möglichkeit, das von meiner Anwendung aus zum Verbinden mitzugeben. Das muß ich noch finden, dann bin ich glücklich. Ein frontendseitiges PW habe ich ja drin, damit man sich bei der Anwendung anmelden muß, aber das hilft ja nix, wenn einer die Datei mopst oder die einfach mit Access öffnet.
Sprachs und auf einmal klappt es auch mit access. Dann baue ich nochmal um, von mdb auf access.
Dieser Beitrag wurde von Holger_N bearbeitet: 23. Juni 2017 - 13:17
Bauernregel: Regnets mächtig im April, passiert irgendwas, was sich auf April reimt.


