 Hilfe
Hilfe
 Neues Thema
Neues Thema


ich hab ein problem mit php. kenn mich damit nicht so gut aus. ich hab ein eingabefeld und da geb ich nen text ein. zeilenumbrüche klappen und die schreibt der auch in ne textdatei.
wenn ich jetzt über php wieder diese textdatei öffne, deren inhalt in das textfeld schreibe wird sie korrekt angezeigt. speicher ich sie jetzt erneut ab in die datei, hab ich am ende jeder zeile ein "^M" ohne " stehen.
woher kommt, ist da ne codierung falsch eingestellt?
*edit* also das ist ^M als ascii code 13. das hab ich jetzt raus. im grunde würd' ich das ja einfach ersetzen, ABER ^M ist auch ein zulässiges Wort in meinem Text... *grml* wie könnte man das lösen oO
danke im vorraus,
lod14
*edit 2*
der fehler ist total komisch
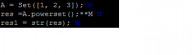
da sind die ^M. ich hab jetzt testweise mal ^M direkt in das textfeld eingetippt.
das wird korrekt weiterverabeitet, spricht es wird **M draus gemacht.
*eigentlich* müsste der die anderen ^M auch durch **M ersetzen. DAS tut der aber nicht.
die ^M stehen auch nicht direkt in der datei drinne, die php rausschreibt.
die datei wird weiterverarbeitet von java. und das, was java da rausschreibt, da stehen dann hinterher die ^M drinne... hääää=?
Dieser Beitrag wurde von LoD14 bearbeitet: 10. November 2009 - 21:07







